
YouTube se cae en medio mundo y salpica a otras compañias
La última gran caída de YouTube ha vuelto a recordar hasta qué punto el funcionamiento de internet depende de un puñado de proveedores tecnológicos. En la noche del martes, alrededor de las 20.00 horas en la Costa Este de Estados Unidos (02.00 en España), la plataforma de vídeo dejó de cargar su página principal y de reproducir contenidos para cientos de miles de usuarios. El portal de incidencias Downdetector llegó a registrar más de 300.000 avisos solo en Estados Unidos, mientras las notificaciones se multiplicaban también desde Europa, Latinoamérica y Asia. La incidencia no afectó únicamente a la web y la aplicación de YouTube, sino también a servicios asociados como YouTube Music, YouTube Kids y YouTube TV, que durante cerca de una hora mostraron mensajes de error o pantallas en blanco. Poco después, la compañía reconocía el problema en redes sociales y admitía que sus equipos estaban investigando el origen del fallo. El diagnóstico preliminar apunta a un error en el sistema de recomendaciones, que impidió que los vídeos se mostraran correctamente en las distintas superficies de la plataforma.


Un apagón global en hora punta
La cronología de la caída muestra por qué el impacto fue tan visible. Según los registros de Downdetector, los primeros reportes masivos comenzaron en torno a las 20.00 horas (ET), justo en la franja de mayor consumo de vídeo en Estados Unidos. En pocos minutos, el contador de incidencias superaba los 300.000 avisos acumulados, una cifra que, como siempre en este tipo de herramientas, solo refleja a los usuarios que deciden reportar el problema, no el total de afectados.
El fallo se manifestó de varias formas: para algunos, la página de inicio no cargaba; otros podían entrar en la web, pero no reproducir vídeos; y muchos usuarios de YouTube TV se encontraron con errores al iniciar sesión o al cambiar de canal. En la práctica, se trató de una interrupción casi total de la experiencia de uso, especialmente en dispositivos móviles y televisores conectados, donde la plataforma es hoy el equivalente a una gran cadena generalista.
El efecto geográfico se extendió con rapidez. Usuarios de India informaron de más de 17.000 incidencias en los minutos siguientes, mientras que los reportes desde Reino Unido, México o Australia se contaban por miles. El patrón fue el habitual: primero Estados Unidos, luego una oleada mundial a medida que los usuarios intentaban identificar si el problema era de su conexión o de la plataforma.
Lo más significativo, sin embargo, no fue solo el número de afectados, sino la velocidad con la que un fallo localizado se tradujo en un apagón global percibido en tiempo real.
Un mapa de fallos que va más allá de YouTube
Minutos después del pico de incidencias en YouTube, los gráficos de Downdetector comenzaron a dibujar un segundo patrón preocupante: el de otros grandes servicios que también empezaban a registrar problemas. El buscador de Google, su matriz, Alphabet Inc., y la infraestructura en la nube de Amazon Web Services (AWS) mostraron picos de varios miles de incidencias casi en paralelo.
En Estados Unidos se contabilizaron más de 2.600 reportes vinculados a Google, alrededor de 1.000 a AWS y unos 400 a los servicios de red de Cloudflare, según los datos públicos del agregador. Aunque estas cifras son muy inferiores a las de YouTube, el solapamiento temporal sugiere una interdependencia sistémica entre servicios que, sobre el papel, deberían ser redundantes.
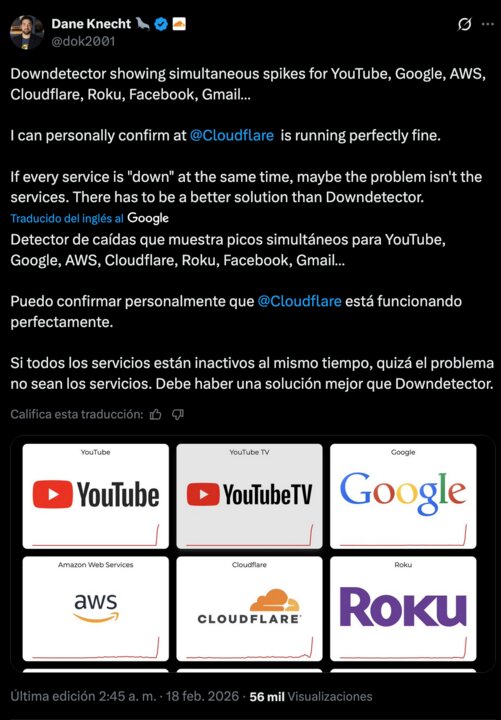
En este contexto, Downdetector vuelve a situarse en el centro del debate. El propio director de Tecnología de Cloudflare, Dane Knecht, salió al paso de las gráficas en la red social X para subrayar que su red estaba funcionando “perfectamente bien” y que los picos de incidencias reflejaban, sobre todo, el número de usuarios que entraban a comprobar si el servicio estaba caído. «Si todos los servicios aparecen ‘caídos’ al mismo tiempo, quizá el problema no sean los servicios», vino a decir, cuestionando la fiabilidad de tratar Downdetector como una fuente autoritativa.
Mientras tanto, YouTube optó por un mensaje prudente en la red social X. «Si tienes problemas para acceder a YouTube ahora mismo, no estás solo: nuestros equipos están investigando y compartiremos novedades en cuanto las tengamos», vino a decir la compañía en su primera comunicación pública.
La combinación de estos elementos —picos simultáneos en varios gigantes, mención a problemas en la capa de certificados y una explicación inicial centrada en el sistema de recomendaciones— dibuja un panorama más complejo que un simple “servidor caído”.

El papel de Google, AWS y Cloudflare
Para entender la magnitud del incidente hay que mirar más allá de la interfaz de YouTube y descender a las entrañas de la infraestructura que sostiene la plataforma. Aunque el servicio pertenece a Google, su funcionamiento se apoya en una compleja combinación de centros de datos propios, servicios de nube interna y, en menor medida, redes de terceros que facilitan el transporte de datos y la seguridad de las conexiones.
En ese ecosistema, empresas como AWS y Cloudflare juegan un rol clave. AWS domina cerca del 30% del mercado mundial de infraestructura en la nube, seguida de Microsoft Azure y Google Cloud, que suman juntos más de un 60% del gasto empresarial en servicios cloud a escala global. Es decir, tres compañías soportan la mayor parte del tráfico y el procesamiento de datos del mundo corporativo y de los grandes servicios digitales de consumo.
Cloudflare, por su parte, actúa como una especie de autopista y escudo: ofrece red de distribución de contenidos (CDN), protección frente a ataques DDoS y servicios de seguridad que se interponen entre el usuario y el servidor final.
Una dependencia crítica de pocos proveedores
La caída de YouTube subraya un diagnóstico que los reguladores llevan años repitiendo: la hiperconcentración de la infraestructura digital en un reducido número de actores. Según distintas estimaciones, los tres grandes proveedores de nube concentran en torno al 60-65% del mercado mundial de infraestructura cloud, una proporción que no deja de crecer.
En la práctica, esto significa que una enorme parte de la economía digital —desde plataformas de vídeo hasta fintech, logística o administración electrónica— descansa sobre los mismos cimientos. Cuando uno de estos cimientos se resquebraja, aunque sea durante 60 o 90 minutos, los efectos se sienten de forma transversal: caen webs, se ralentizan pagos, se interrumpen servicios críticos y se multiplican los costes ocultos para empresas que nada tienen que ver con el origen del incidente.
El contraste con otros sectores es evidente. Pocas industrias estratégicas aceptarían que tres compañías controlasen más de dos tercios de la capacidad global sin mecanismos robustos de redundancia obligatoria o supervisión específica. Sin embargo, en la nube pública, la lógica de mercado y las economías de escala han empujado a gobiernos y empresas a concentrar cada vez más cargas de trabajo en estos “hiperescaladores”, a menudo sin planes alternativos reales.
Este hecho revela una paradoja incómoda: cuanto más eficiente y barata resulta la nube de los grandes proveedores, más cara se vuelve una hora de caída para el conjunto del sistema.

Antecedentes: cuando internet se apaga en cadena
El episodio de YouTube no es un caso aislado, sino el último de una lista creciente de grandes apagones digitales. En octubre de 2025, una interrupción masiva en Amazon Web Services dejó fuera de servicio durante horas a plataformas tan populares como redes sociales, servicios de vídeo, videojuegos online o aplicaciones educativas.
Antes, entre 2022 y 2024, varias caídas de los servicios de Google —desde su buscador hasta Gmail o Google Maps— provocaron fallos generalizados en media internet, obligando a la compañía a reconocer problemas en actualizaciones de software o en su red de centros de datos. Y en noviembre de 2025, la ya mencionada incidencia de la nube provocó errores simultáneos en servicios tan dispares como Spotify, X, ChatGPT o portales de noticias, recordando que incluso las herramientas diseñadas para dar resiliencia pueden convertirse en un punto único de fallo.
El denominador común de todos estos casos es claro: una combinación de complejidad técnica extrema y concentración de funciones críticas. En sistemas de esta escala, un error de configuración, un fallo en la propagación de certificados o una actualización defectuosa pueden propagarse en cuestión de segundos por cientos de centros de datos distribuidos en decenas de países.
La consecuencia es inequívoca: cada nuevo incidente refuerza la percepción de que internet se ha convertido en una infraestructura tan crítica como la red eléctrica o el sistema financiero… pero sin un marco de supervisión igualmente exigente.
Impacto económico de una hora sin vídeo
A primera vista, una caída de YouTube puede parecer un problema menor comparado con un fallo en un sistema de pagos o en una red eléctrica. Sin embargo, el peso económico del vídeo online desmiente esa intuición. La plataforma acumula más de 2.000 millones de usuarios registrados y es uno de los principales escaparates publicitarios del mundo. Una interrupción de una hora en hora punta implica millones de impresiones no servidas, campañas detenidas y métricas que se desajustan en el último minuto.
Para los creadores de contenido, el impacto es doble. Por un lado, la pérdida directa de ingresos publicitarios en franjas de máxima audiencia; por otro, la alteración de algoritmos que premian la constancia y la retención de la audiencia. En un entorno donde muchos canales viven de márgenes muy estrechos, unas pocas horas de caída repetidas a lo largo del año pueden equivaler a varios puntos porcentuales de facturación perdida.
Además, YouTube se ha convertido en el canal prioritario de muchas marcas para lanzar productos, retransmitir eventos o gestionar su atención al cliente. Una interrupción imprevista obliga a reprogramar directos, redirigir tráfico a otras plataformas o asumir la frustración de usuarios que no reciben el servicio prometido. El coste reputacional, aunque difícil de cuantificar, se acumula.
La consecuencia es clara: cada nueva caída erosiona la confianza de anunciantes y empresas en la fiabilidad absoluta del ecosistema digital, y alimenta el debate sobre si es prudente concentrar tanta inversión en un número tan reducido de plataformas.


